Publications
A collection of my research work.
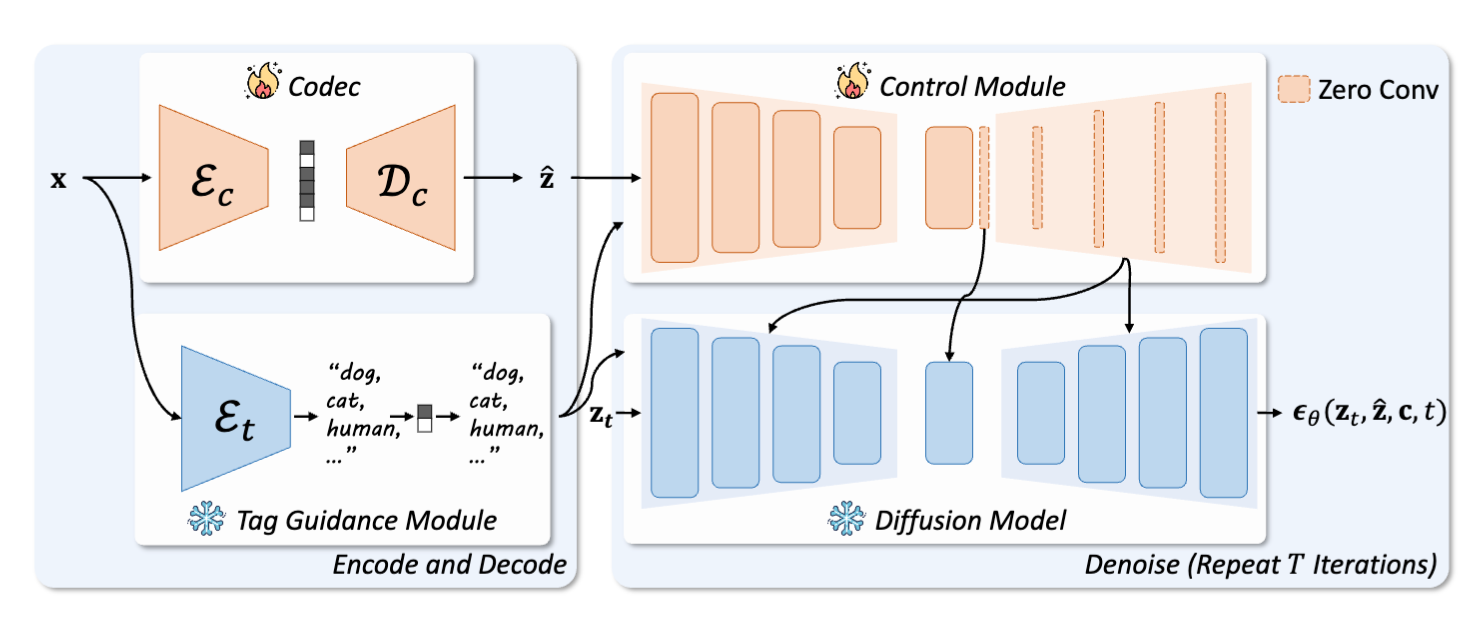
Diff-ICMH: Harmonizing Machine and Human Vision in Image Compression with Generative Prior
Ruoyu Feng, Yunpeng Qi, Jinming Liu, Yixin Gao, Xin Li, Xin Jin, Zhibo Chen
The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) 2025
Harmonizing machine and human vision in image compression using generative priors from diffusion models.
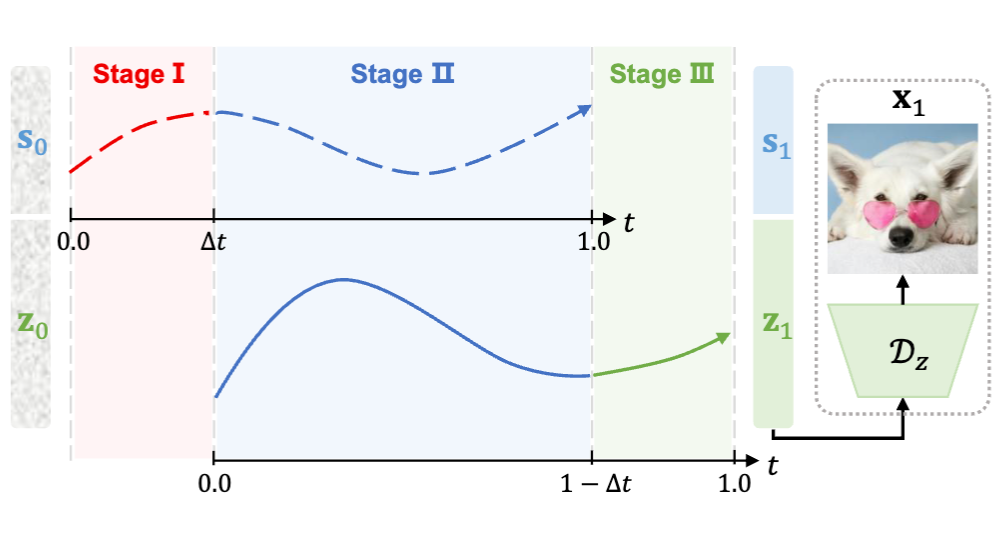
Semantics Lead the Way: Harmonizing Semantic and Texture Modeling with Asynchronous Latent Diffusion
Yueming Pan†, Ruoyu Feng†, Qi Dai, Yuqi Wang, Wenfeng Lin, Mingyu Guo, Chong Luo, Nanning Zheng
2025
Harmonizing semantic and texture modeling using asynchronous latent diffusion for improved image generation.
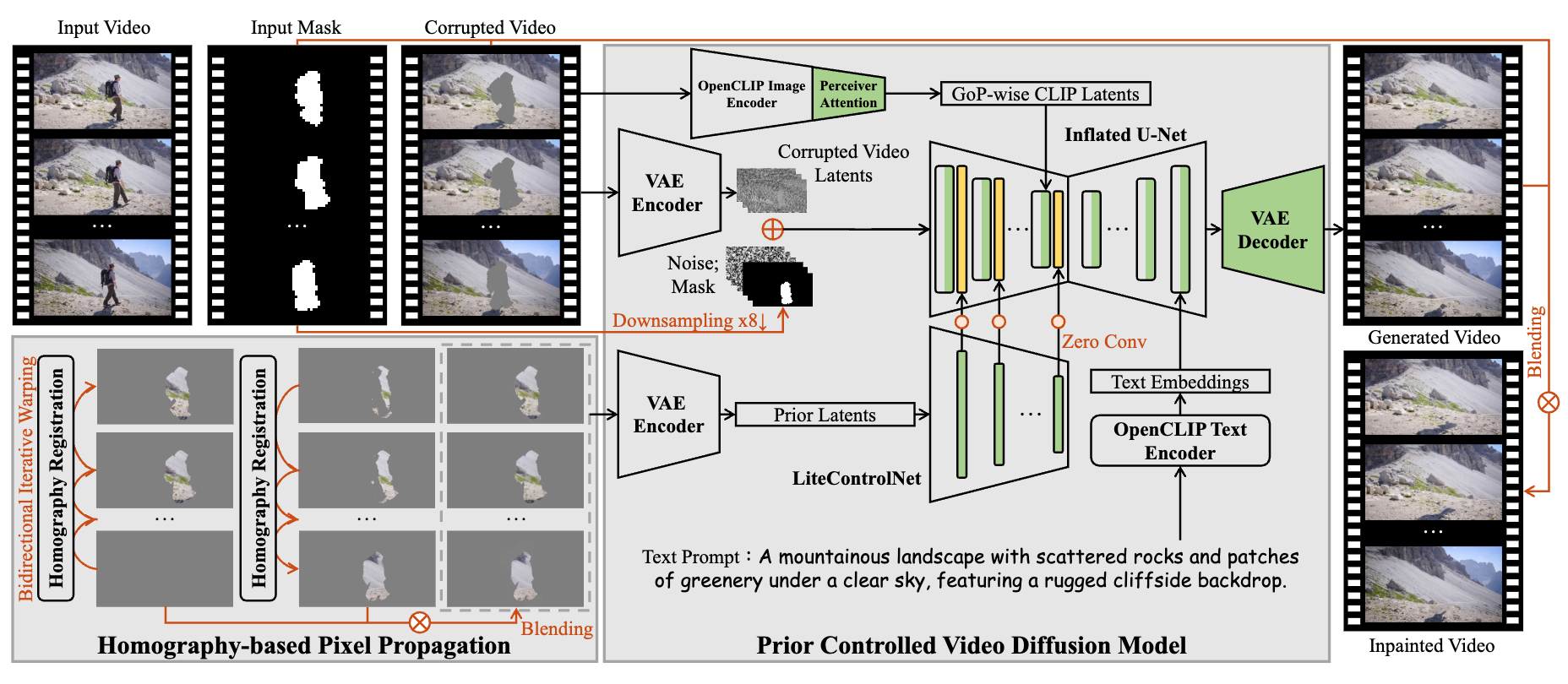
HomoGen: Enhanced Video Inpainting via Homography Propagation and Diffusion
Ding Ding, Yueming Pan, Ruoyu Feng, Qi Dai, Kai Qiu, Jianmin Bao, Chong Luo, Zhenzhong Chen
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) 2025
Enhanced video inpainting method using homography propagation and diffusion models.

ContentV: Efficient Training of Video Generation Models with Limited Compute
Wenfeng Lin, Renjie Chen, Boyuan Liu, Shiyue Yan, Ruoyu Feng, Jiangchuan Wei, Yichen Zhang, Yimeng Zhou, Chao Feng, Jiao Ran, others
arXiv preprint arXiv:2506.05343 2025
Efficient video generation model training framework optimized for limited computational resources.
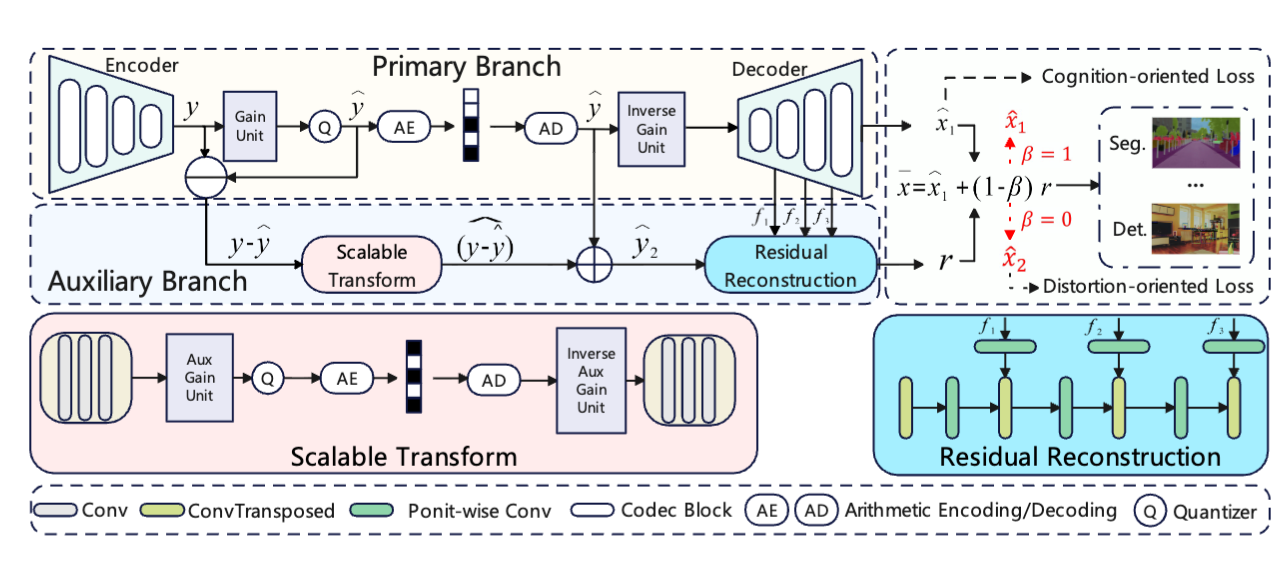
Rate-distortion-cognition controllable versatile neural image compression
Jinming Liu, Ruoyu Feng, Yunpeng Qi, Qiuyu Chen, Zhibo Chen, Wenjun Zeng, Xin Jin
European Conference on Computer Vision (ECCV) 2024
Versatile neural image compression with controllable rate-distortion-cognition trade-offs.
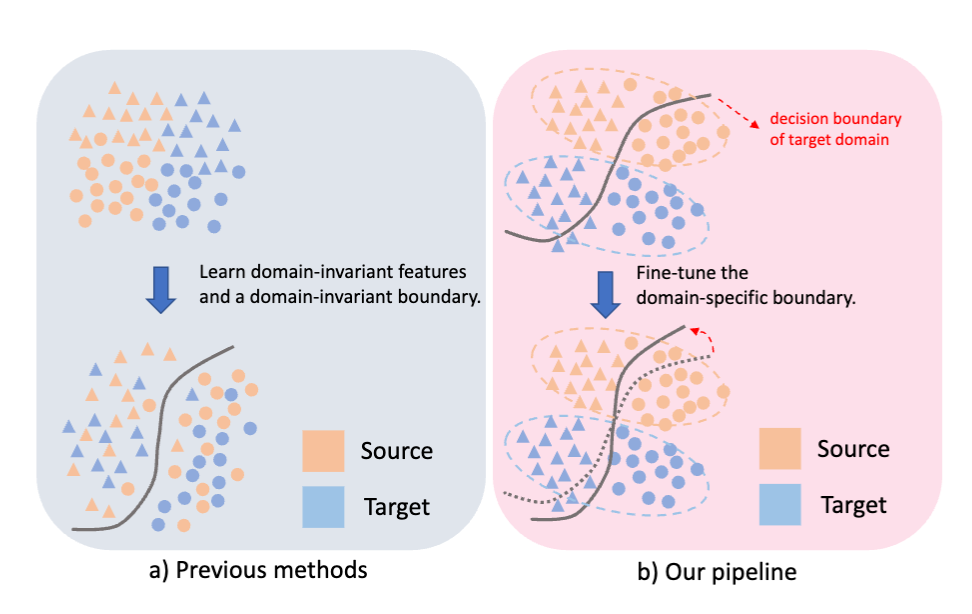
Rethinking domain adaptation and generalization in the era of clip
Ruoyu Feng, Tao Yu, Xin Jin, Xiaoyuan Yu, Lei Xiao, Zhibo Chen
2024 IEEE International Conference on Image Processing (ICIP) 2024
Novel perspective on domain adaptation and generalization leveraging CLIP foundation models.

CCEdit: Creative and Controllable Video Editing via Diffusion Models
Ruoyu Feng, Wenming Weng, Yanhui Wang, Yuhui Yuan, Jianmin Bao, Chong Luo, Zhibo Chen, Baining Guo
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Creative and controllable video editing framework using diffusion models.
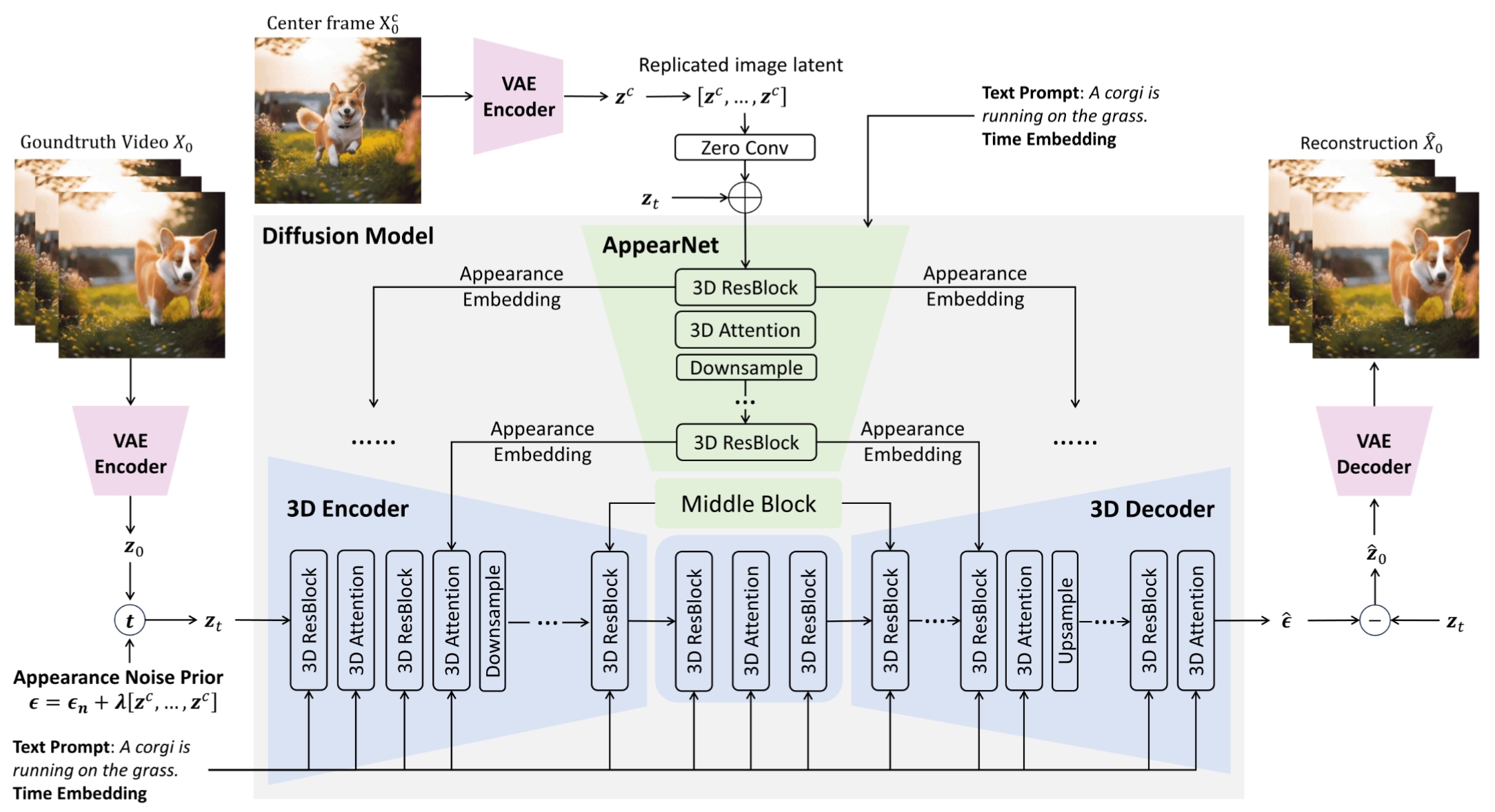
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
Yanhui Wang, Jianmin Bao, Wenming Weng, Ruoyu Feng, Dacheng Yin, Tao Yang, Jingxu Zhang, Qi Dai, Zhiyuan Zhao, Chunyu Wang, Kai Qiu, Yuhui Yuan, Xiaoyan Sun, Chong Luo, Baining Guo
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR Highlight) 2024
Divide-and-conquer approach for text-to-video generation, accepted as CVPR Highlight.
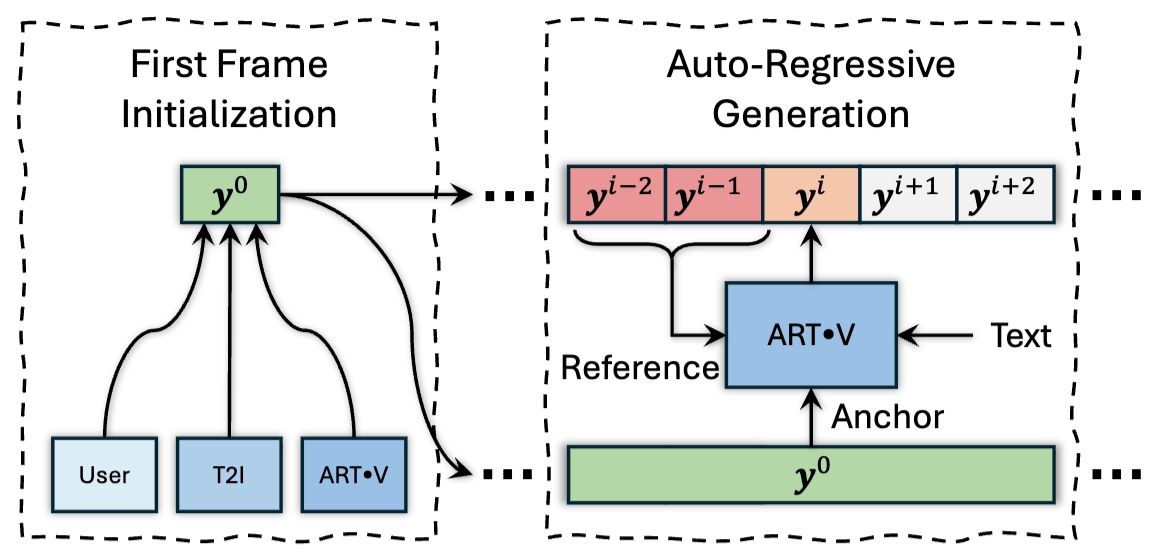
ART·V: Auto-Regressive Text-to-Video Generation with Diffusion Models
Wenming Weng, Ruoyu Feng, Yanhui Wang, Qi Dai, Chunyu Wang, Dacheng Yin, Zhiyuan Zhao, Kai Qiu, Jianmin Bao, Yuhui Yuan, Chong Luo, Yueyi Zhang, Zhiwei Xiong
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Auto-regressive text-to-video generation framework with diffusion models.
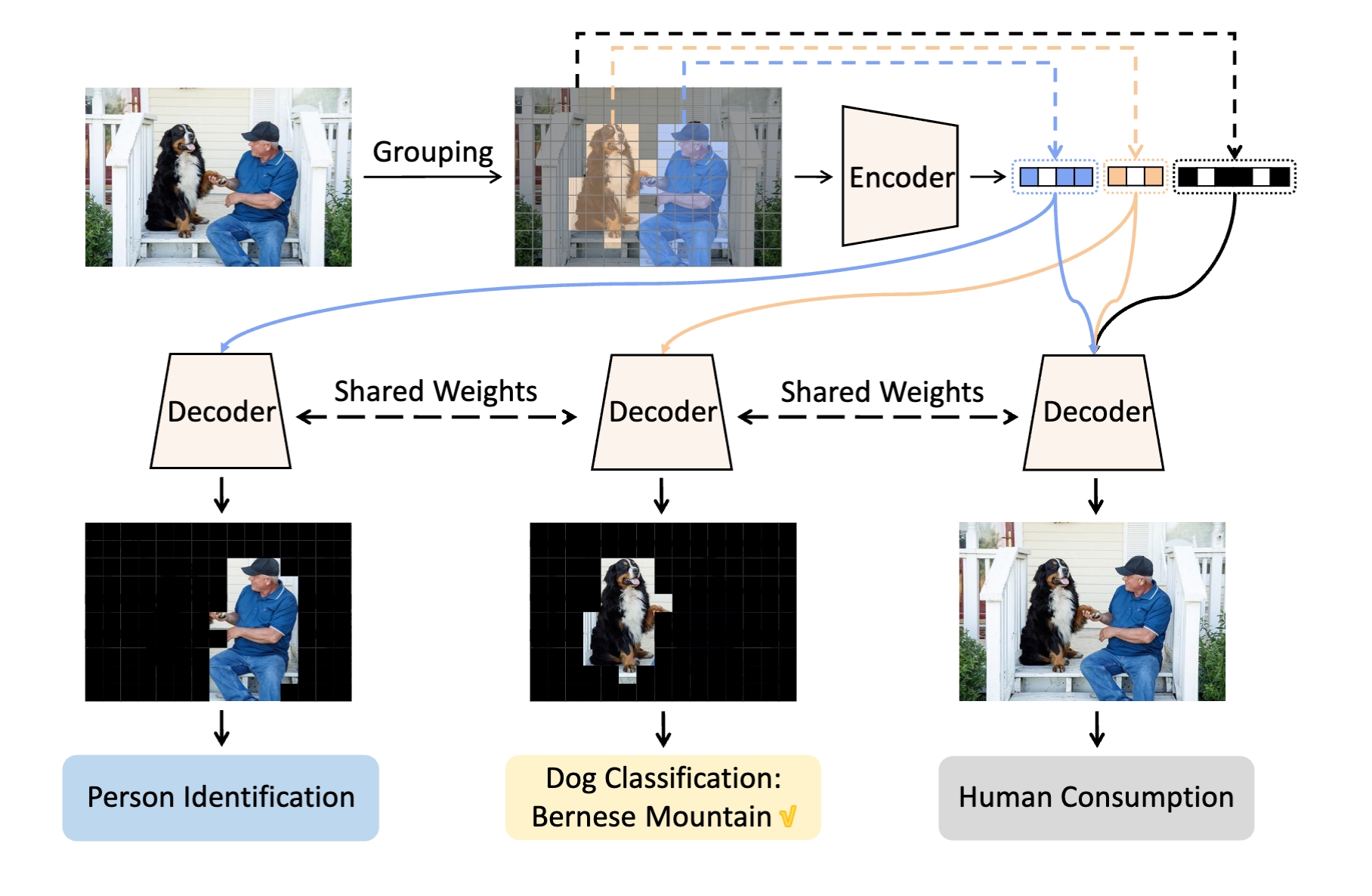
Semantically Structured Image Compression via Irregular Group-Based Decoupling
Ruoyu Feng†, Yixin Gao†, Xin Jin, Runsen Feng, Zhibo Chen
International Conference on Computer Vision (ICCV) 2023
Novel image compression approach using semantic structure and irregular group-based decoupling.
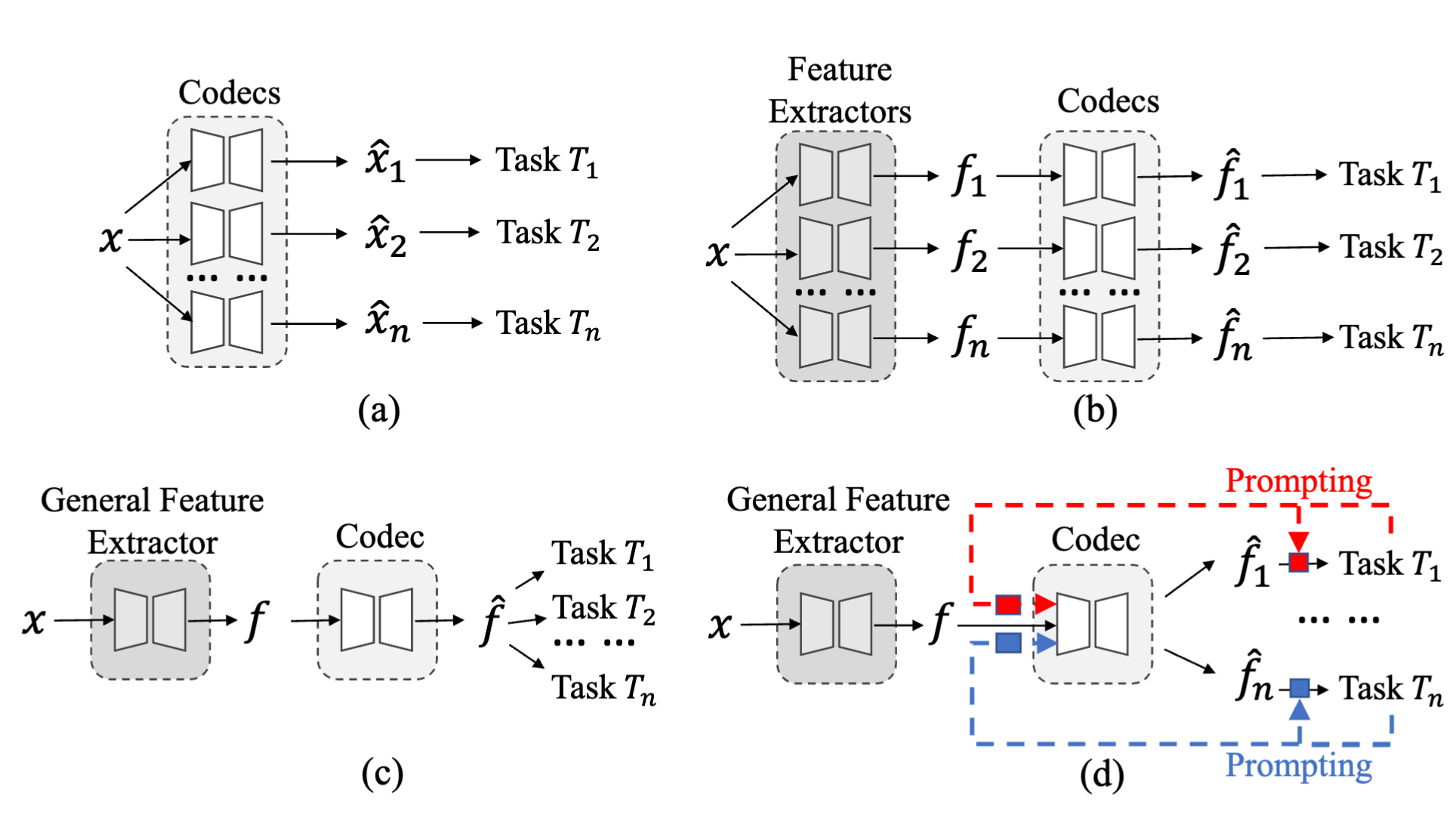
Prompt-ICM: A Unified Framework towards Image Coding for Machines with Task-driven Prompts
Ruoyu Feng†, Jinming Liu†, Xin Jin, Xiaohan Pan, Heming Sun, Zhibo Chen
arXiv preprint 2023
Unified framework for image coding for machines using task-driven prompts.
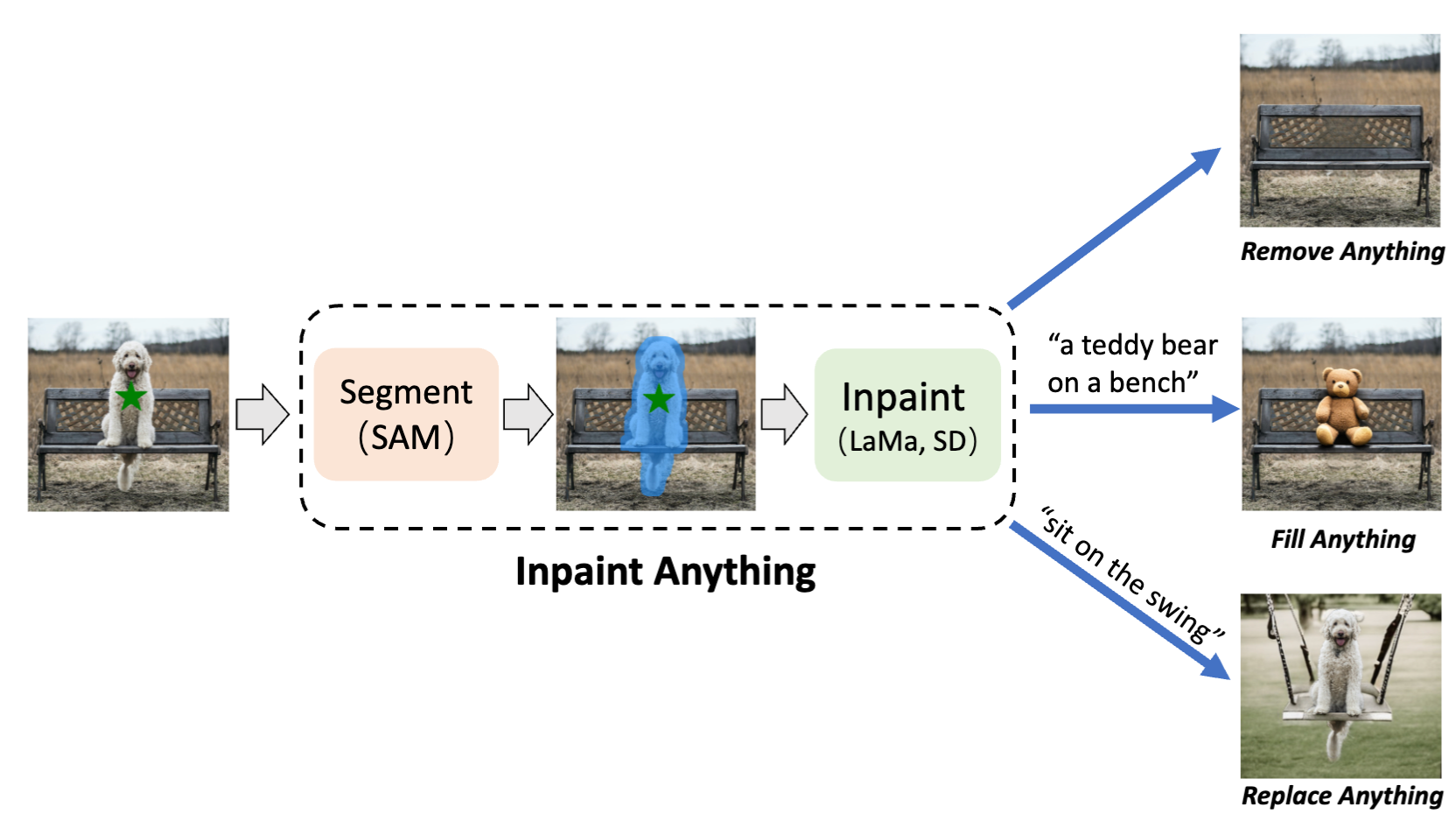
Inpaint Anything: Segment Anything Meets Image Inpainting
Tao Yu, Runsen Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, Zhibo Chen
arXiv preprint 2023
Combining Segment Anything Model with image inpainting for versatile editing.
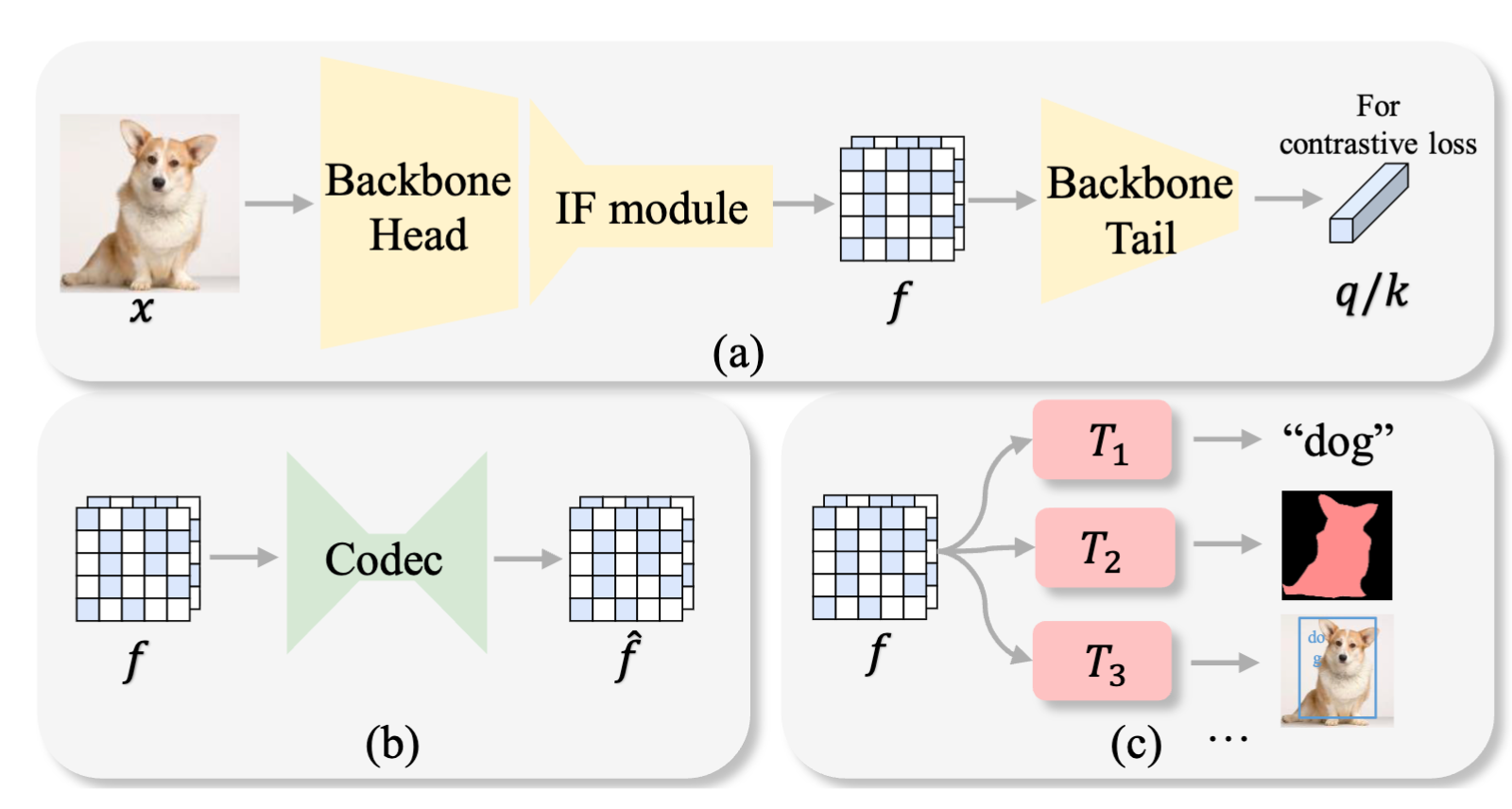
Image Coding for Machines with Omnipotent Feature Learning
Ruoyu Feng†, Xin Jin†, Zongyu Guo, Runsen Feng, Yixin Gao, Tianyu He, Zhizheng Zhang, Simeng Sun, Zhibo Chen
European Conference on Computer Vision (ECCV) 2022
Omnipotent feature learning framework for image coding targeting machine vision tasks.
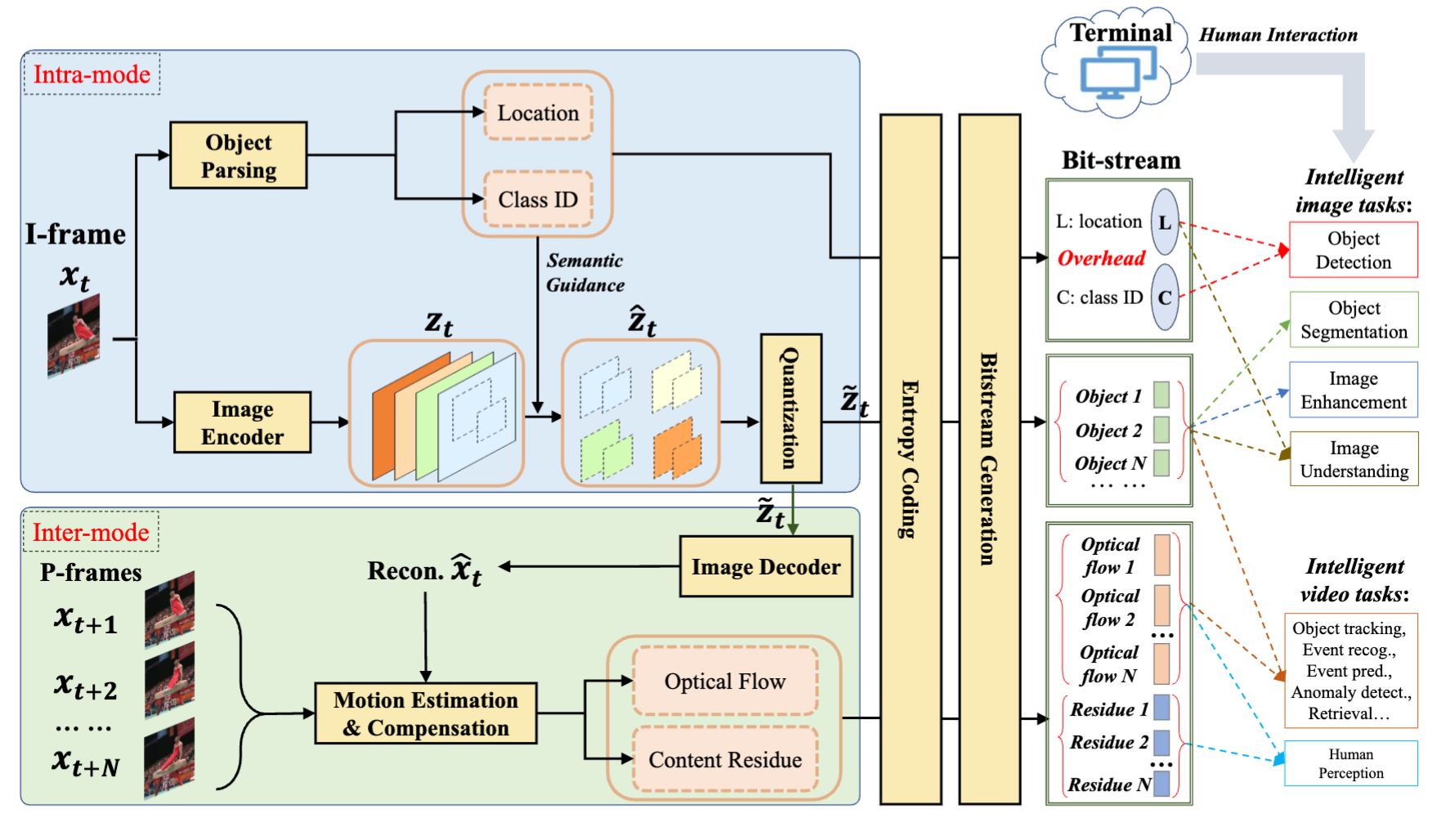
Semantical Video Coding: Instill Static-Dynamic Clues into Structured Bitstream for AI Tasks
Xin Jin†, Ruoyu Feng†, Simeng Sun†, Runsen Feng, Tianyu He, Zhibo Chen
Journal of Visual Communication and Image Representation (JVCIR) 2022
Semantical video coding approach incorporating static-dynamic clues for AI tasks.
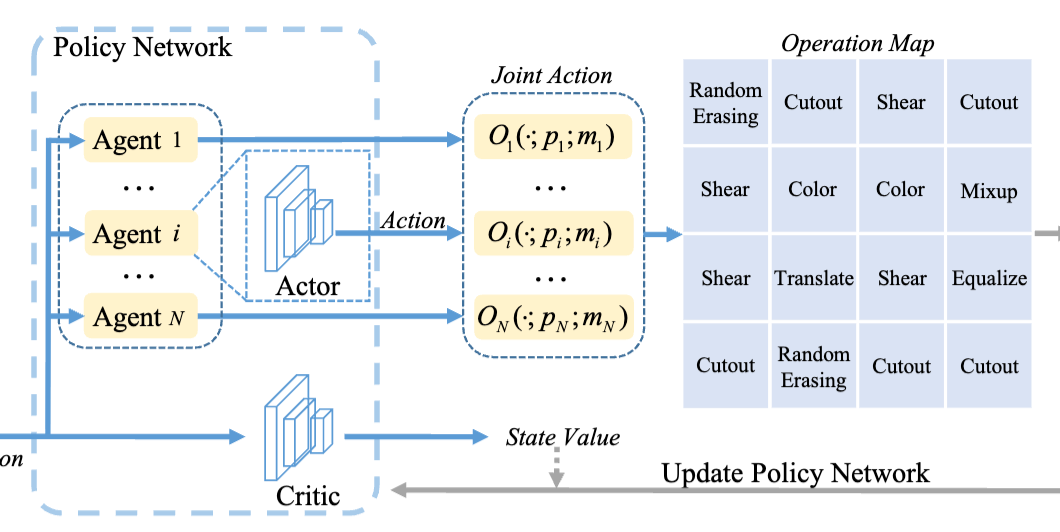
Local Patch AutoAugment with Multi-Agent Collaboration
Shiqi Lin, Tao Yu, Ruoyu Feng, Xin Li, Xiaoyuan Yu, Lei Xiao, Zhibo Chen
IEEE Transactions on Multimedia (TMM) 2021
Multi-agent collaboration framework for local patch auto-augmentation.